
Continuamos con el tercer apartado del tercer capítulo de Probability Theory and Statistical Inference, de Aris Spanos.
Si vemos como sólo una función del punto final del intervalo
, entonces podemos definir la distribución acumulada (cdf):
Ahora sí hemos generado una función que relaciona el número real asignado a cada posible evento con su probabilidad de ocurrencia. Pero en este caso es la probabilidad acumulada.
Para el caso simple (discreto) tenemos la función de densidad:
Por tanto, los espacios probabilísticos pueden simplificarse en el caso de variables aleatorias discretas y continuas a los siguientes:
Spanos se plantea en este punto si se pueden definir funciones de densidad para variables continuas y funciones de distribución para variables discretas, y la respuesta es que sí.
La estatura de los jugadores de la NBA se puede considerar como una variable continua. Desde el inicio de la NBA hasta el año 2015, hay 3984 jugadores cuya estatura se muestra en este archivo.
El histograma de la distribución es el siguiente:
data:read_list(file_search("RUTADELARCHIVO.txt "));
datatranspose:transpose(data);
estatura:datatranspose;
histogram (
estatura,
nclasses=15,
frequency=density,
xlabel="Espacio muestral. Estatura jugadores NBA (cm)",
ylabel="Densidad de probabilidad",
fill_color=green,
fill_density=0.5);
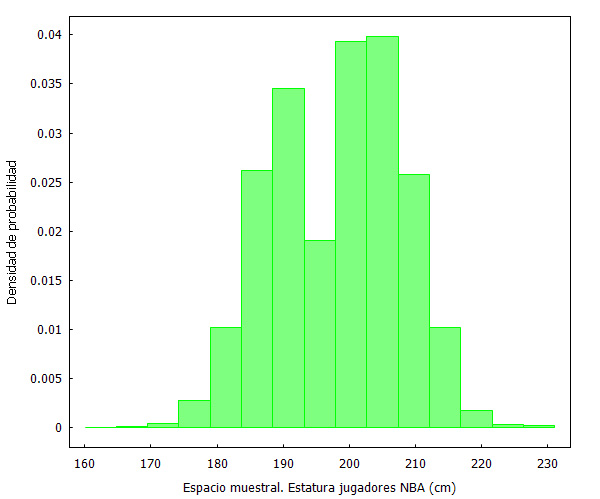
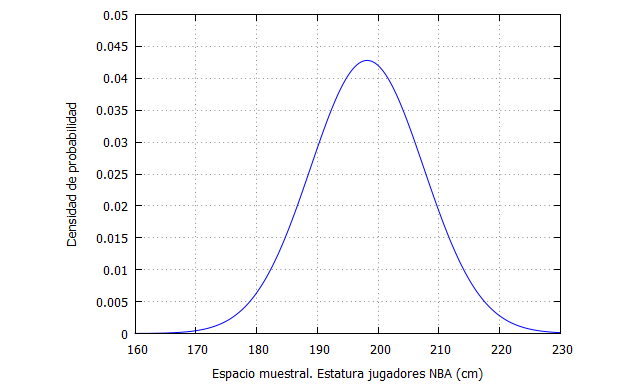
Es una distribución que se aproxima a una Normal, pero que no sabemos realmente si lo es. Recordemos que una distribución Normal tiene como función de densidad:
De este modo, podemos tomar como media y desviación típica la de la muestra, como una estimación de los parámetros poblacionales.
El resultado, tras emplear Stata 13.0, es el mostrado en el gráfico siguiente:
Sin embargo, otras distribuciones también podrían ajustarse a los datos. Por ejemplo, la distribución Weibull:
También la distribución logística podría ajustarse aproximadamente bien a los datos:
En Maxima podemos representar las 3 distribuciones, Normal, Weibull y logística, de la siguiente forma:
load(distrib); plot2d([pdf_weibull(x,18,198.2),pdf_logistic(x,198.2,5.5), pdf_normal (x, 198.2, 9.32)], [x,160,230],[y,0,0.05], [xlabel, "Espacio muestral. Estatura jugadores NBA (cm)"], [ylabel, "Densidad de probabilidad"], [legend, "Weibull", "Logistica", "Normal"]);
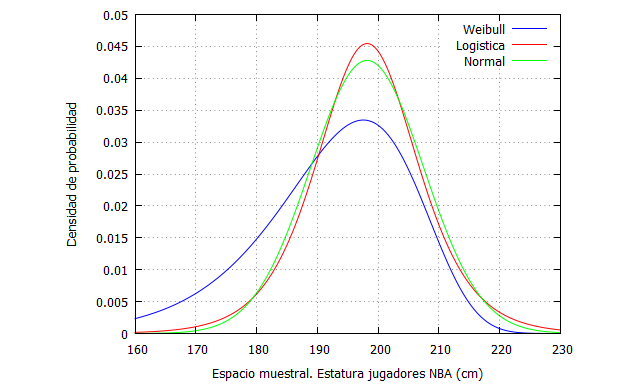
Las 3 distribuciones consideradas, estipulan que . Esto es un elemento a tener en cuenta porque en este caso tenemos una distribución de estatura cuyos valores no pueden ser nunca cero o menor que cero. Por tanto,
. Desde el punto de vista práctico quizá para este ejemplo no tenga demasiada importancia, pero a nivel didáctico nos sirve para justifica la búsqueda de otra función de densidad que sólo permita valores positivos.
Una opción es emplear la función chi-cuadrado:
donde r son los grados de libertad y es la función Gamma.
Así, para r=198, y con la ayuda de Stata 13.0, vemos la distribución chi-cuadrado en azul.
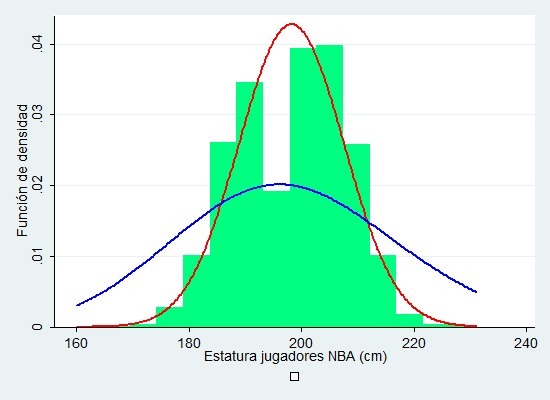
Como se puede apreciar, el ajuste no es tan bueno como la distribución Normal, aunque pese a que la Normal tenga un rango de valores teórico fuera del permitido por este caso.
En definitiva, hemos visto que podemos simplificar los espacios probabilísticos empleando funciones de densidad y de distribución. Así, con la adecuada elección de la función de densidad podemos relacionar los eventos con su probabilidad de ocurrencia, teniendo en cuenta que en distribuciones continuas lo pertinente es analizar la probabilidad entre 2 puntos de la distribución.