
En este artículo publicado en el Australasian Marketing Journal, los autores discuten alguno de los pros y de los contras de PROCESS, un método para el análisis de variables mediadoras y moderadas en procesos causales.
Mediación y moderación
Los investigadores, en la siguiente figura, muestran algunos de los modelos más habituales en ciencias sociales en los que aparecen variables mediadoras y moderadoras.
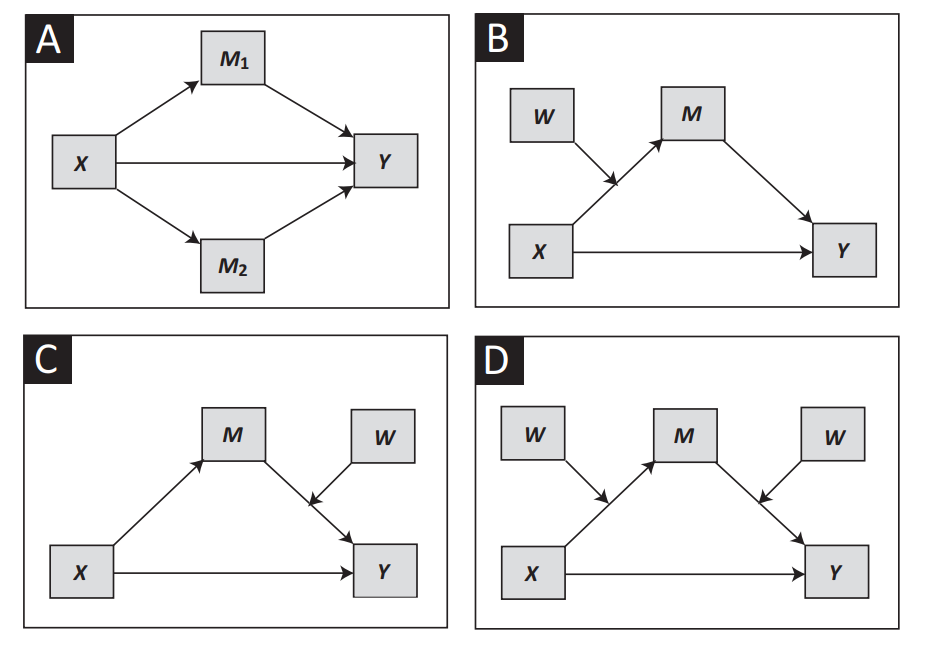
En el modelo A, las variables M1 y M2 median la relación causal entre X e Y. Esto significa que X afecta a Y de dos formas diferentes: directamente, e indirectamente a través de M1 y M2.
En el caso de los modelos B, C y D, tenemos la variable W que modera la relación causal entre dos variables, ya sea entre X y M o entre M e Y. Una variable moderadora es una variable que interactúa con la causa de manera multiplicativa.
El método de PROCESS
Este método es propuesto por Hayes (2013), y es simplemente una herramienta computacional (un macro para ciertos programas como SPSS, SAS o R), que realiza regresiones por separado basándose en estimación por mínimos cuadrados ordinarios. Por ejemplo, para el modelo A, se necesitan tres ecuaciones, una para la variables Y, otra para la variable M1, y otra para la variable M2. Los errores estándar de los parámetros se estiman empleando bootstrapping.
Ecuaciones estructurales vs PROCESS
Los autores comparan PROCESS con los modelos de ecuaciones estructurales (SEM). En la Figura mostrada anteriormente se puede apreciar la facilidad con la que SEM puede actuar, estimando de una sola vez el modelo completo, y proveyendo un índice de ajuste.
Sin embargo, para los autores, dado que en ocasiones los modelos propuestos son saturados (como ocurre en el modelo A), los índices de ajuste no proveen ningún tipo de información de interés.
No obstante, los autores admiten la ventaja de SEM para considerar múltiples indicadores de cada concepto y, con ello, los errores de medida, algo que PROCESS no puede hacer. Es por ello que Pek & Hoyle (2016), recomiendan SEM frente a PROCESS.
Los autores, para ejemplificar que no existen diferencias relevantes entre los resultados de aplicar PROCESS y SEM, realizan un análisis con ambas metodologías a un modelo con un solo mediador. Las estimaciones de los parámetros son casi idénticas, aunque no así los errores estándar, debido lógicamente a los diferentes métodos de estimación. Como el modelo es saturado, el ajuste es perfecto, por lo que los índices de ajuste no aportan información añadida.
Comentarios personales
En mi opinión, SEM es una herramienta mucho más completa que PROCESS. Desde el punto de vista epistemológico, SEM provee una forma clara de testar una teoría frente a los datos empíricos, planteando desde el inicio un modelo de partida que, de forma completa, es puesto a prueba empíricamente.
Es evidente, además, que si el investigador emplea varios indicadores (casi siempre ítems) por variable latente, es preceptivo usar SEM en lugar de (como desafortunadamente se suele hacer), promediar los indicadores para quedarse con un solo índice por variable, y entonces aplicar PROCESS. Esta forma de proceder es errónea si no existe tau-equivalencia.
Otra limitación de PROCESS frente a SEM es lo poco que se tiene en cuenta la adecuación estadística del modelo, es decir, testar las asunciones probabilísticas. No obstante, también es cierto que la exigencia de la normalidad multivariante para la estimación por máxima verosimilitud en SEM puede ser un problema en determinados modelos.
Dado que la moderación es una interacción, PROCESS maneja de forma sencilla la programación del modelo. Sin embargo, en SEM, si la variable moderadora es dicotómica, se debe realizar un análisis multigrupo del modelo (el modelo, además, debe ajustarse vía chi-cuadrado en los dos grupos). Si la variable moderadora es continua, realizar esa especificación con SEM es mucho más complejo a nivel de variables latentes.
En conclusión, PROCESS puede ser una alternativa en casos muy específicos, pero SEM es una herramienta mucho más completa y recomendable, que parte de una idea básica en ciencia, que es el planteamiento de un modelo teórico y su puesta a prueba con los datos empíricos. Con los grados de libertad adecuados, SEM informa sobre la validez de esa especificación (chi-cuadrado), una vez cumplidas las asunciones probabilísticas en las que se basa el modelo propuesto.
Referencia
Hayes, A. F., Montoya, A. K., & Rockwood, N. J. (2017). The analysis of mechanisms and their contingencies: PROCESS versus structural equation modeling. Australasian Marketing Journal (AMJ), 25(1), 76–81. https://doi.org/10.1016/j.ausmj.2017.02.001