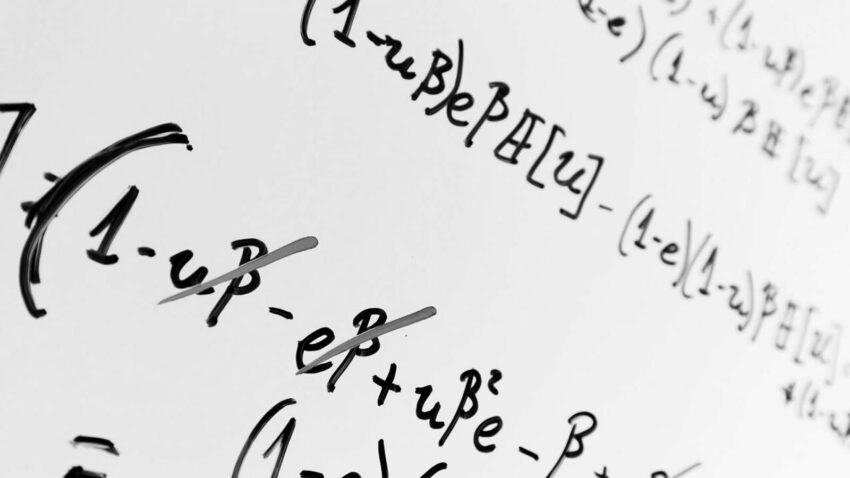
En este segundo paso en nuestra introducción a conceptos básicos de SEM, vamos a explicar el concepto de variable latente y las implicaciones que tiene para la partición de la varianza observable, lo que a su vez nos llevará a discutir sobre la fiabilidad de los datos.
Variable latente
Una variable latente Z es, por definición, no observable directamente, por lo que se manifiesta a través de algún observable z, que usualmente es llamado indicador. Es fácil deducir la siguiente ecuación:
z=bZ+e
donde b es el coeficiente estructural (a veces llamado “peso”) que define la escala del observable con respecto a la variable latente, y e es el error inherente a tener una observación que puede ser una simplificación de Z (porque es un término muy abstracto y complejo de aproximar), o porque, por ejemplo, haya errores de codificación o de registro en la recogida de datos. Este último hecho es esencial para entender qué significa que exista un error de medida y nos hace ver que todas las variables que manejemos pueden considerarse latentes porque, aunque sean variables aparentemente sencillas (ej. sexo, edad), siempre pueden estar sujetas a error en el proceso de recogida y preparación de los datos.
Ahora podemos tomar esperanzas y varianzas para ver qué ocurre con la ecuación anterior:
E(z)=bE(Z)+E(e); 0=b(0)+0
Var(z)=b2Var(Z)+Var(e)
Si estamos manejando ya datos en desviaciones con respecto a la media como hablamos en el capítulo 1, no nos deben sorprender esos resultados.
La forma de representar gráficamente esta relación sigue unas normas muy sencillas. Con círculos u ovoides se representan las variables latentes y con cuadrados o rectángulos los indicadores observables. La relación entre esas variables viene determinada por flechas que tienen un sentido causal, es decir, apuntan desde la causa hasta el efecto, desde donde se produce el cambio hasta donde se manifiesta dicho cambio (ver Figura 2.1).
Figura 2.1. Esquema básico de variable latente y observable
Como se aprecia en la Figura 2.1, el error e es también una variable latente, porque realmente no lo observamos, pero sabemos que existe. Y el sentido de las flechas es capital; ambas variables latentes afectan causalmente al indicador observable, ya que el cambio en ellas se manifiesta en un cambio en el indicador.
Así, si el error se mantiene constante y Z crece, también crece z en función del peso que tenga b. Y si Z se mantiene constante, z puede variar en la medida que lo haga el error de medición. Ese error de medición hemos supuesto que es ruido blanco, es decir, se considera aleatorio, por lo que no sesga el observable, sino que cuando se realizan muchas medidas, los errores se compensan, y de ahí que su esperanza matemática sea cero.
Aunque parezca una asunción fuerte, realmente no lo es. Si sospechamos que existe algún tipo de error sistemático en lugar de aleatorio siempre se puede incorporar al modelo. Por ejemplo, si z es la edad que medimos en una muestra de consumidores, es posible que el error e no sea aleatorio porque haya un grupo de personas que digan a la baja su edad (sesgo de presentación favorable). Pero este hecho se puede fácilmente modelar en SEM, de la siguiente manera (Figura 2.2.):
Figura 2.2. Esquema básico de variable latente y observable con un sesgo sistemático
De este modo, la ecuación quedaría así:
Var(z)=b2Var(Z)+m2Var(M)+Var(e)
Es decir, hemos introducido una nueva variable latente M, que influye con un peso m en el observable z, y que tiene en cuenta el sesgo producido por la presentación favorable. Así, seguiríamos manteniendo e como ruido blanco, y tendríamos un modelo que contemplar una causa adicional a la variación del observable z.
Fiabilidad
Pero estamos todavía muy al comienzo de la andadura en SEM, y debemos ir resolviendo las cuestiones más sencillas antes de las más complejas.
Volvamos, por tanto, a la ecuación básica:
Var(z)=b2Var(Z)+Var(e)
Hemos partido la varianza observable en la varianza real Var(Z) más la varianza de error Var(e). Recordemos que las varianzas siempre son positivas.
Si Var(e)=0, significa que la varianza observable es igual a la varianza de error, siempre que se midan en la misma escala, es decir, b=1. Por medir en la misma escala nos referimos a que si estamos midiendo la variable latente está en metros, el indicador observable lo vamos a medir en metros, o si está en una escala de 0 a 10, el observable lo vamos a medir en una escala de 0 a 10. Es algo muy recomendable que escalemos siempre con b=1, ya que esto nos evita de cometer muchos errores innecesarios.
De este modo, si Var(e)=0, los datos son totalmente fiables, en el sentido de que no hay error de medida, por tanto la fiabilidad es del 100%. Pero claro, una de las ventajas de SEM es que nos permite ser prudentes y admitir en nuestro modelo que puede haber algún error de medida que haga que la fiabilidad no sea del 100%.
¿Pero cómo se mide la fiabilidad cuando hay error de medida? Es sencillo, porque depende únicamente del tamaño relativo de la varianza de error.
Fiabilidad=1-(Var(e)/Var(z))
O en porcentaje:
Fiabilidad=(1-(Var(e)/Var(z)))100
Por tanto, a medida que la varianza de error se incrementa disminuye la fiabilidad. Es evidente que son preferibles fiabilidades altas, porque en el grado en que la fiabilidad sea más baja la varianza observable Var(z) será más alta, es decir, se produce un inflado de la varianza de los datos que luego tiene efectos notables en la estimación de los coeficientes estructurales del modelo, produciendo una atenuación de los mismos (el efecto estimado es menor que el real, por lo que hay un sesgo). Con SEM podemos tener en cuenta esos errores de medida y obtener coeficientes insesgados con fiabilidades diferentes del 100%, y esta es otra de la grandes ventajas de esta metodología.
La relación que existe entre el cociente Var(e)/Var(z) y la fiabilidad se muestra en la Figura 2.3.
Figura 2.3. Fiabilidad en función del tamaño relativo de la varianza de error
Para obtener esa figura hemos empleado el siguiente código de Stata:
|
/*Generamos una variable con 100 observaciones cuyos valores van del 1 al 100*/ |
Por tanto, para fijar la fiabilidad del indicador observable sólo hay que escoger el porcentaje de la varianza observada que constituye la varianza de error. Así, si por ejemplo Var(z)=5, y la fiabilidad es fijada al 90%, entonces Var(e)/Var(z)=0.10, por lo que la Var(e) debe fijarse a 0.05, es decir, un 10% de la varianza del indicador observable.
Conclusión
Hemos visto que es muy atractivo poder considerar a todas las variables que manejamos en nuestros modelos teóricos como latentes, incluso en los casos más sencillos donde esas variables no sean abstracciones psicológicas, sino variables claramente definidas y cuantificables.
Esto permite especificar errores de medida, que no son más que el tamaño relativo de la varianza de error, y de este modo indicar la fiabilidad de las mediciones, realizando (como veremos posteriormente) diferentes simulaciones con respecto a cómo variarían los resultados ante fiabilidades distintas.
1 thought on “BÁSICOS DE ECUACIONES ESTRUCTURALES (II): VARIABLES LATENTES Y FIABILIDAD”
Comments are closed.